一、GPU#
Graphics Processing Unit (GPU) 最初是作为一种专门用于 3D 图形的处理器诞生的。2003 年,GPU 的一些阶段变得完全可编程,可以为 3D 场景或图像的每个组件并行运行自定义代码。2006 年,NVIDIA 推出了 Compute Unified Device Architecture (CUDA),使任何计算密集工作负载都能够独立于图形 API 使用 GPU 的吞吐能力。
从那时起,CUDA 和 GPU 计算已被用于加速几乎所有类型的计算工作负载,从科学模拟(如流体动力学或能量传输)到商业应用(如数据库和分析)。此外,GPU 的能力和可编程性为新算法和技术的进步奠定了基础,从图像分类到生成式人工智能(如扩散模型或大型语言模型)。
和 CPU 相比,GPU 的优点是:
- 高并行性
- 高指令吞吐和内存带宽
- 高能效
CPU 重点是提升单线程性能,GPU 通过牺牲单线程性能,并行执行大量线程来提升整体吞吐。
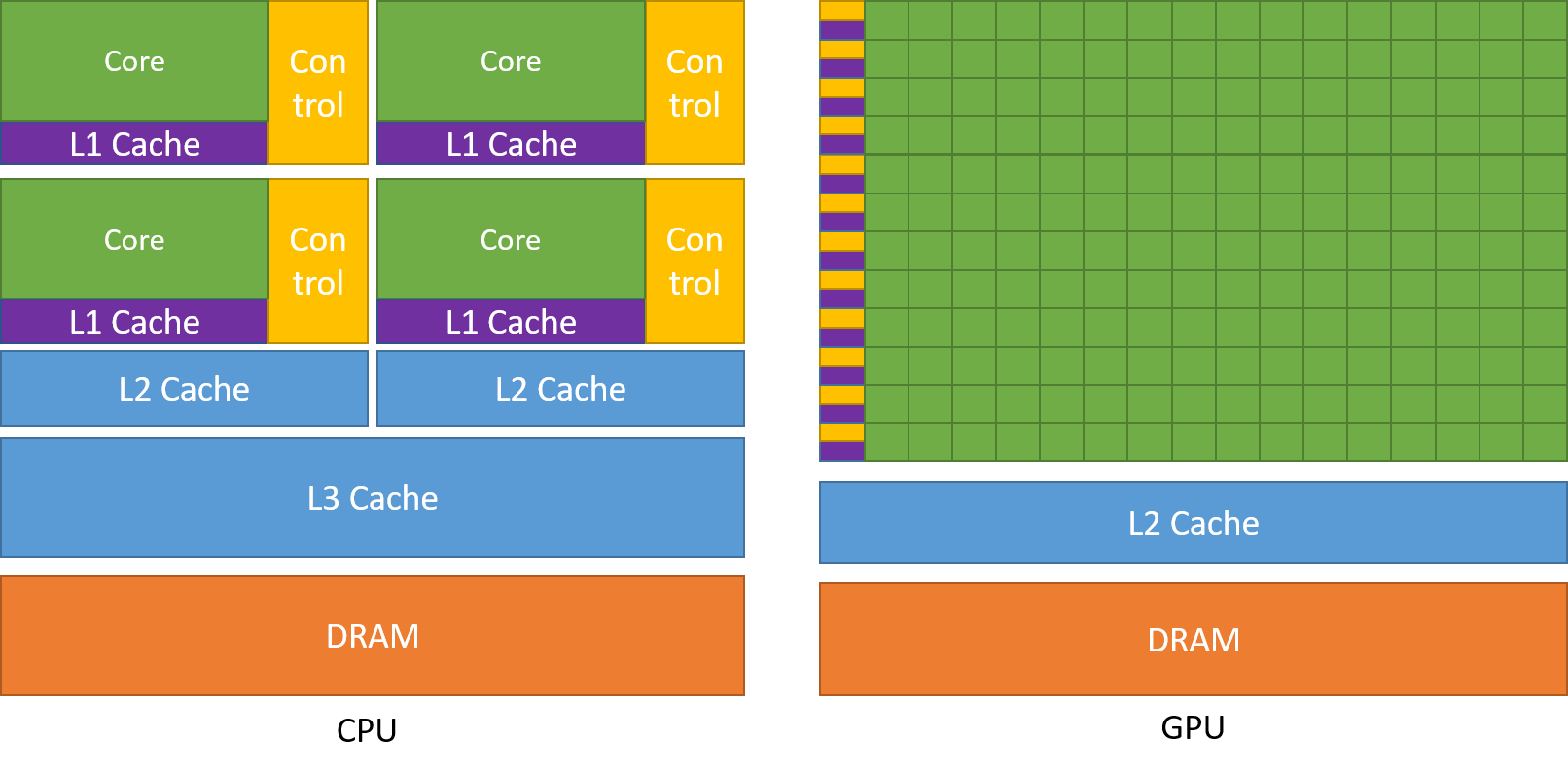
从图中可以看出来,GPU 绝大部分面积用于数据处理,而 CPU 则用于缓存和控制单元。
二、CUDA 编程模型#
1. 异构系统#
CPU 和直接连接到 CPU 的内存被称为 host 和 host memory。与之相对地,GPU 和直接连接到 GPU 的内存被称为 device 和 device memory。在一些 SoC 中它们可能是单个封装的一部分,在更大的系统中可能有多个 CPU 和 GPU。
CUDA 应用从 host 启动,并且在 GPU 上执行部分代码。通常 host 代码使用 CUDA API 来分配 GPU 内存、将数据从 host 复制到 device、启动 GPU 上的内核,并将结果从 device 复制回 host。CPU 和 GPU 上的代码可以同时执行。
GPU 上执行的代码叫做 device 代码,被调用的函数叫做 kernel。每个 kernel 在 GPU 上并行执行许多线程,每个线程执行相同的代码,但使用不同的数据。
2. GPU 硬件模型#
GPU 由多个 Streaming Multiprocessors (SM) 组成。每个 SM 包含本地寄存器文件,一个统一的数据缓存,以及计算单元。如何把缓存分配为 shared memory 和 L1 是可运行时配置的。
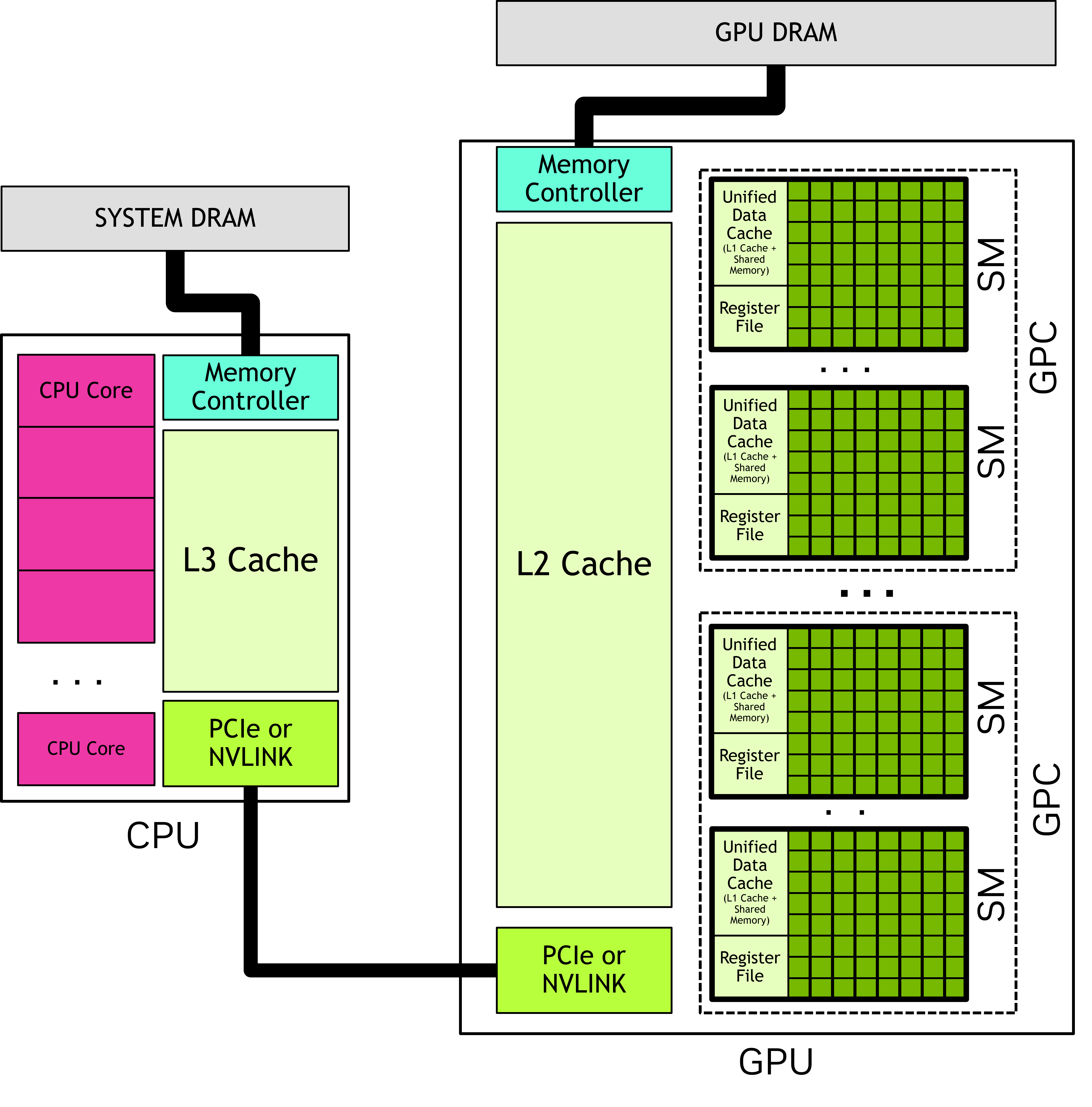
在 GPU 上并行执行的大量线程按照如下方式组织:
- 1D/2D/3D Grid 包含多个 Thread Block
- 1D/2D/3D Thread Block 包含多个 Thread

其中网格和线程块的维度需要在内核启动时指定。
在 kernel 内部,每个线程可以通过 threadIdx、blockIdx 和 blockDim 内置变量来计算其全局线程 ID,从而确定它应该处理哪个数据元素。
一个 thread block 中的所有线程始终在单个 SM 上执行,所以它们之间可以高效通信和同步(使用 on-chip shared memory)。
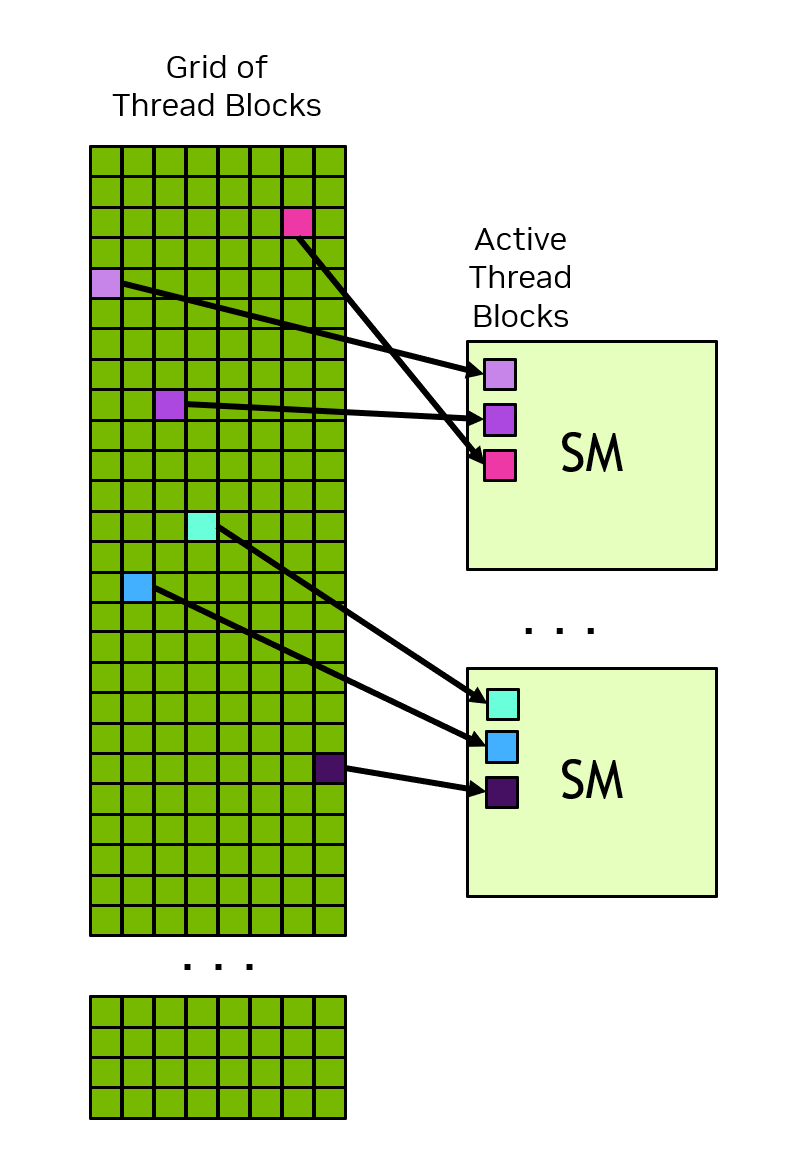
大量的 block 会被调度到 GPU 几十/几百个 SM 上。block 之间的执行顺序不确定,因此不能依赖其它 block 的状态或结果。
除此之外,grid 中相邻的 block 可以分组为 cluster(CUDA 计算能力 9.0 以上)。
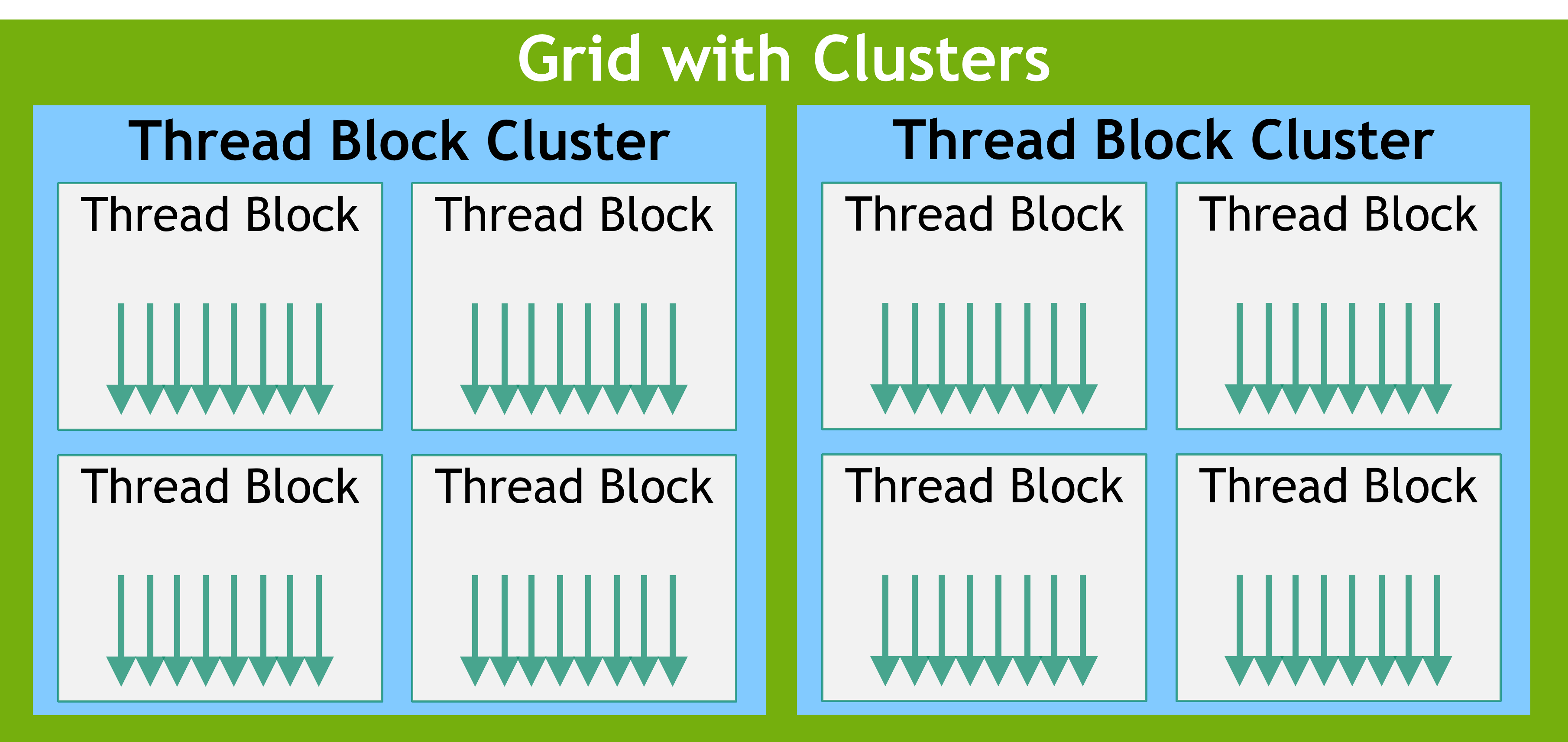
不同 block 但是在同一个 cluster 的线程可以通过 Cooperative Groups API 进行通信和同步。同一个 cluster 的线程可以访问到 distributed shared memory。cluster 的大小取决于具体硬件。
在一个 thread block 内部,线程被分成大小为 32 的 warp。一个线程束中的所有线程同时执行相同的指令,Single-Instruction Multiple-Threads (SIMT)。一个线程块中的线程数量应该是 32 的倍数,以避免资源浪费。
线程由 warp 执行的时候会被分配一个 warp lane ID (0-31),并按照(可预测的)硬件多线程执行。
warp 中的线程执行指令时,如果遇到分支语句,一部分为真一部分为假,那么先屏蔽条件为假的线程,等待条件为真的线程执行完指令后,再屏蔽条件为真的线程,等待条件为假的线程执行完指令。

这种现象叫做 warp divergence。为了获得最佳性能,应该尽量避免 warp 内的线程进入不同的控制流路径。
三、CUDA 内存模型#
1. DRAM#
直接连接到 GPU 的 DRAM 叫做 global memory,因为它可以被所有 SM 访问。在目前所有系统上 GPU 和 CPU 使用单个全局虚拟地址空间。内存的分配,复制和释放由 CUDA API 管理。
2. 片上存储#
可编程的部分是每个 SM 上的 register(通常由编译器分配)和 shared memory。这两者是 SM 的一部分,访问速度非常快,但是不能跨 SM 共享。shared memory 可以用来在同一个 block/cluster 内的线程之间共享数据和进行通信。
把一个 block 调度到 SM 上面时,单个线程需要的寄存器数 线程数 可用的寄存器数。否则无法 launch kernel。
不可编程的部分包括 L1/L2 cache。L1 在 SM 内部,和 shared memory 共享资源(占比可配置),L2 在 GPU 内部,所有 SM 之间共享。除此之外,SM 内还有 constant cache,用来存 global memory 中在 kernel 生命周期内被声明为常数的数据。
四、CUDA 平台#
1. Compute Capability#
每个 NVIDIA GPU 都有一个 Compute Capability (CC) 版本号,表示该 GPU 支持的特性和部分硬件参数。CC 通常写成 X.Y,例如 8.0、9.0、12.0。
CC 也对应 SM 版本,比如 compute capability 12.0 对应 sm_120,这是 CUDA 编译 GPU 二进制时使用的目标架构名。
2. CUDA Toolkit 和 NVIDIA Driver#
NVIDIA Driver 可以理解为 GPU 的操作系统,负责让系统使用 GPU。CUDA Toolkit 则是开发 CUDA 程序需要的编译器、头文件、库和分析工具。
CUDA Runtime API 是 Toolkit 提供的常用高级接口,底层建立在 CUDA Driver API 之上。一般 CUDA C++ 程序主要使用 Runtime API;需要更细粒度控制时,也可以直接使用 Driver API。
3. PTX#
PTX (Parallel Thread Execution) 是 NVIDIA GPU 的虚拟指令集,可以理解为一种中间表示。高层语言代码通常先编译成 PTX,再被编译成具体 GPU 可执行的二进制代码。
PTX 也有版本,例如 compute_80 表示面向 compute capability 8.0 的 PTX。因为 PTX 可以在运行时 JIT 编译,所以它常用于兼容未来的 GPU 架构。
4. Cubin 和 Fatbin#
cubin 是面向具体 SM 版本的 GPU 二进制代码,例如 sm_86、sm_90。它加载快,但只能在兼容的 GPU 上运行。
fatbin 是 CUDA 程序中存放 GPU 代码的容器,可以同时包含多个架构的 cubin,也可以包含 PTX。程序运行时,驱动会为当前 GPU 选择最合适的代码;如果没有合适的 cubin,但有兼容的 PTX,则可以通过 JIT 编译生成。
二进制兼容通常只在同一 major compute capability 内成立,例如 sm_86 可以在 8.6 或 8.9 上运行,但不能在 8.0 或 9.0 上运行。