一、GPU 内存空间#
| 内存类型 | 范围 | 生命周期 | 物理位置 |
|---|---|---|---|
| Global | Grid | 程序运行期间 | Device |
| Local | Thread | kernel 运行期间 | Device |
| Constant | Grid | 程序运行期间 | Device |
| Shared | Block | kernel 运行期间 | SM |
| Register | Thread | kernel 运行期间 | SM |
1. Global Memory#
类似于 CPU 的 RAM,所有线程可访问。手动释放或者应用结束时自动释放。容量大,访问延迟较高(约 400-600 个时钟周期)。
因为 kernel 只能返回 void,所以返回数值结果必须写回 global memory。
1__global__ void vecAdd(float* A, float* B, float* C, int vectorLength)
2{
3 int workIndex = threadIdx.x + blockIdx.x*blockDim.x;
4 if(workIndex < vectorLength)
5 {
6 C[workIndex] = A[workIndex] + B[workIndex];这个例子中,A、B 和 C 都是 global memory 中的数组。每个线程计算一个元素的和,并将结果写回 C 数组。
2. Local Memory#
线程私有的内存空间,但是物理上位于 global memory 中(和 global 具有相同的延迟和带宽)。
编译器在这些情况下会使用 local memory 而不是寄存器:
- index 不是常数的数组
- 大的结构体或者数组,register 不足以存储
- 任何变量,如果 kernel 中的寄存器使用过多(register spilling)
3. Constant Memory#
只读内存,所有线程可访问。需要使用 __constant__ 修饰符在函数外声明和初始化。
典型的大小为 64KB。
1// In your .cu file
2__constant__ float coeffs[4];
3
4__global__ void compute(float *out) {
5 int idx = threadIdx.x;
6 out[idx] = coeffs[0] * idx + coeffs[1];
7}
8
9// In your host code
10float h_coeffs[4] = {1.0f, 2.0f, 3.0f, 4.0f};
11cudaMemcpyToSymbol(coeffs, h_coeffs, sizeof(h_coeffs));
12compute<<<1, 10>>>(device_out);4. Shared Memory#
每个 block 内的线程共享的内存空间。物理上位于 SM 内部,和 L1 共享资源(unified data cache)。访问延迟较低(约 1-5 个时钟周期)。
使用 __shared__ 修饰符声明共享内存变量。
线程块中的线程可以通过 shared memory 进行通信,为了避免 data race 必须同步。
1#include <cuda_runtime.h>
2#include <iostream>
3
4// assuming blockDim.x is 128
5__global__ void example_syncthreads(int *input_data, int *output_data) {
6 __shared__ int shared_data[128];
7 // Every thread writes to a distinct element of 'shared_data':
8 for (int i = 0; i < threadIdx.x; i++) {
9 shared_data[threadIdx.x] = input_data[threadIdx.x];
10 }
11
12 // All threads synchronize, guaranteeing all writes to 'shared_data' are
13 // ordered before any thread is unblocked from '__syncthreads()':
14 __syncthreads();
15
16 // A single thread safely reads 'shared_data':
17 if (threadIdx.x == 32) {
18 int sum = 0;
19 for (int i = 0; i < blockDim.x; ++i) {
20 sum += shared_data[i];
21 }
22 output_data[blockIdx.x] = sum;
23 }
24}
25
26int main() {
27 size_t size = sizeof(int) * 128;
28
29 int *h_input_data;
30 int *h_output_data;
31
32 cudaMallocHost(&h_input_data, size);
33 cudaMallocHost(&h_output_data, size);
34
35 for (int i = 0; i < 128; i++) {
36 h_input_data[i] = i;
37 }
38
39 int *d_input_data;
40 int *d_output_data;
41
42 cudaMalloc(&d_input_data, size);
43 cudaMalloc(&d_output_data, size);
44
45 cudaMemcpy(d_input_data, h_input_data, size, cudaMemcpyHostToDevice);
46
47 example_syncthreads<<<128, 128>>>(d_input_data, d_output_data);
48
49 cudaMemcpy(h_output_data, d_output_data, size, cudaMemcpyDeviceToHost);
50
51 for (int i = 0; i < 128; i++) {
52 std::cout << h_output_data[i] << ' ';
53 }
54 std::cout << std::endl;
55
56 cudaFree(&d_input_data);
57 cudaFree(&d_output_data);
58
59 cudaFreeHost(&h_input_data);
60 cudaFreeHost(&h_output_data);
61
62 return 0;
63}在这个例子中,先到达 __syncthreads() 的线程会被阻塞,直到 block 中的所有线程都到达这个点。之后,线程 32 安全地读取 shared_data 中的值并计算总和:
1nvcc example_syncthreads.cu -o example_syncthreads
2./example_syncthreads
38128 8128 8128 8128 ... (128 times)如果我们去掉 __syncthreads() 那一行,那么线程 32 可能在其他线程写入 shared_data 之前就读取了它,导致结果不确定:
1nvcc example_syncthreads.cu -o example_syncthreads
2./example_syncthreads
38008 7632 8128 8128 8008 8008 8008 8122 8008 8128 8128 8008 8008 8128 8128 7632 8008 8008 7632 8128 8128 8008 8008 8008 8128 8008 8008 8008 8122 8008 7632 8128 8128 7632 8008 8128 8008 8008 8008 7632 7632 8008 8128 8122 7632 8008 8008 8008 8008 8008 8008 7632 7632 8128 7632 7632 8008 8008 7632 7632 8008 8008 7750 7632 8008 8128 8128 8128 7632 7852 7632 7632 8128 8128 8128 7632 8008 8128 8008 7632 8008 7852 7852 7852 8128 8008 8128 8128 7750 8008 8128 8128 8128 8128 7750 8128 8008 7632 7852 8008 8100 7852 8008 7632 8008 8128 8128 8100 8008 8128 8008 8008 8008 8128 8100 7938 7632 8128 8128 8128 8128 8128 8128 8128 8128 8128 8128 8128 shared memory 可以静态分配或者运行时动态分配。
静态分配:
1__shared__ float sharedArray[1024];此后 block 中的所有线程都可以访问 sharedArray。注意避免数据竞争。
动态分配:
空间大小在 launch kernel 的时候指定:
1func<<<grid, block, sharedMemSize>>>(...);kernel 中使用 extern __shared__ 声明动态共享内存空间并用指针运算进行分区:
1extern __shared__ float array[];
2
3short* array0 = (short*)array;
4float* array1 = (float*)&array0[128];
5int* array2 = (int*)&array1[64];
6
7// 相当于如下静态分配
8short array0[128];
9float array1[64];
10int array2[256];注意指针的地址要和类型对齐,比如这种写法不行:
1extern __shared__ float array[];
2short* array0 = (short*)array;
3float* array1 = (float*)&array0[127];5. Register#
物理上位于 SM 内部,由编译器自动分配和管理。
可以手动指定 kernel 函数的寄存器数量上限,这样可能可以让 SM 同时调度更多 block,但是也可能造成更多寄存器溢出。
6. Caches#
L2 在 device 内部,所有 SM 共享。L1 在 SM 内部,和 shared memory 共享资源。例如没有使用 shared memory,所有物理空间都会分配给 L1。
缓存的一些行为可以配置。
7. Distributed Shared Memory#
单个 block 的 shared memory 太小,整个 grid 同步/共享太破坏调度,cluster 是介于 block 和 grid 之间的 trade-off 产物。
每个线程可以访问到 cluster 中其它线程的 shared memory,它们组合成一个 distributed shared memory address space。线程在这个地址空间中可以进行读写和原子操作。
shared memory 的大小和是否使用 DSMEM 无关。总的 DSMEM 大小等于每个 SM 的 shared memory 大小乘以一个 cluster 中 SM 的数量。
访问 DSMEM 中的数据要求所有线程块存在(没有退出)。使用 cluster.sync() 同步。
例子:
1#include <cooperative_groups.h>
2
3// Distributed Shared memory histogram kernel
4__global__ void clusterHist_kernel(int *bins, const int nbins, const int bins_per_block,
5 const int *__restrict__ input, size_t array_size)
6{
7 extern __shared__ int smem[];
8 namespace cg = cooperative_groups;
9 int tid = cg::this_grid().thread_rank();
10
11 // Cluster initialization, size and calculating local bin offsets.
12 cg::cluster_group cluster = cg::this_cluster();
13 unsigned int clusterBlockRank = cluster.block_rank();
14 int cluster_size = cluster.dim_blocks().x;
15
16 for (int i = threadIdx.x; i < bins_per_block; i += blockDim.x)
17 {
18 smem[i] = 0; //Initialize shared memory histogram to zeros
19 }
20
21 // cluster synchronization ensures that shared memory is initialized to zero in
22 // all thread blocks in the cluster. It also ensures that all thread blocks
23 // have started executing and they exist concurrently.
24 cluster.sync();
25
26 for (int i = tid; i < array_size; i += blockDim.x * gridDim.x)
27 {
28 int ldata = input[i];
29
30 //Find the right histogram bin.
31 int binid = ldata;
32 if (ldata < 0)
33 binid = 0;
34 else if (ldata >= nbins)
35 binid = nbins - 1;
36
37 //Find destination block rank and offset for computing
38 //distributed shared memory histogram
39 int dst_block_rank = (int)(binid / bins_per_block);
40 int dst_offset = binid % bins_per_block;
41
42 //Pointer to target block shared memory
43 int *dst_smem = cluster.map_shared_rank(smem, dst_block_rank);
44
45 //Perform atomic update of the histogram bin
46 atomicAdd(dst_smem + dst_offset, 1);
47 }
48
49 // cluster synchronization is required to ensure all distributed shared
50 // memory operations are completed and no thread block exits while
51 // other thread blocks are still accessing distributed shared memory
52 cluster.sync();
53
54 // Perform global memory histogram, using the local distributed memory histogram
55 int *lbins = bins + cluster.block_rank() * bins_per_block;
56 for (int i = threadIdx.x; i < bins_per_block; i += blockDim.x)
57 {
58 atomicAdd(&lbins[i], smem[i]);
59 }
60}使用 cudaLaunchKernelEx 启动,其中 cluster_size 根据 histogram 需要的内存大小决定:
1// Launch via extensible launch
2{
3 cudaLaunchConfig_t config = {0};
4 config.gridDim = array_size / threads_per_block;
5 config.blockDim = threads_per_block;
6
7 // cluster_size depends on the histogram size.
8 // ( cluster_size == 1 ) implies no distributed shared memory, just thread block local shared memory
9 int cluster_size = 2; // size 2 is an example here
10 int nbins_per_block = nbins / cluster_size;
11
12 //dynamic shared memory size is per block.
13 //Distributed shared memory size = cluster_size * nbins_per_block * sizeof(int)
14 config.dynamicSmemBytes = nbins_per_block * sizeof(int);
15
16 CUDA_CHECK(::cudaFuncSetAttribute((void *)clusterHist_kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, config.dynamicSmemBytes));
17
18 cudaLaunchAttribute attribute[1];
19 attribute[0].id = cudaLaunchAttributeClusterDimension;
20 attribute[0].val.clusterDim.x = cluster_size;
21 attribute[0].val.clusterDim.y = 1;
22 attribute[0].val.clusterDim.z = 1;
23
24 config.numAttrs = 1;
25 config.attrs = attribute;
26
27 cudaLaunchKernelEx(&config, clusterHist_kernel, bins, nbins, nbins_per_block, input, array_size);
28}二、内存性能#
1. 合并内存访问#
访问 global memory 是通过一个个大小为 32-byte 的 transaction 进行的。例如,一个线程访问 4-byte 的 float,实际产生的 transaction 大小也是 32 bytes。
为了让访问效率更高,同一个 warp 中的线程应该访问连续的内存地址,这样 warp 内不同线程访问的地址就可以合并到一个 transaction 中。
例子:如果 warp 访问 32 个连续的 float,总共 128 bytes 只需要 4 个 transaction,带宽的利用率为 100%:

最坏的情况下,两个 float 之间的地址相差 32 bytes,导致每个线程访问的地址都在不同的 transaction 中,带宽利用率只有 12.5%:

让相邻线程访问相邻的地址不是唯一的办法,只要 warp 中的线程访问同一个 32-byte segment 就能合并。
2. Shared Memory 访问#
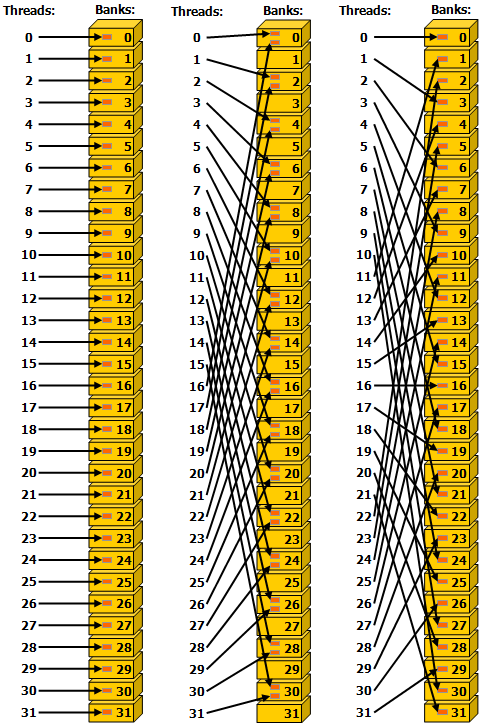
shared memory 有 32 个 bank,每个 bank 可以同时处理一个访问请求,地址空间中相邻的 32-bit 放在相邻的 bank 中。每个 bank 的带宽为每周期 32 bits。
如果同一个 warp 中的多个线程同时访问同一个 bank 中的不同元素时就会 bank conflict,此时多个请求会变成串行的,造成性能损失。
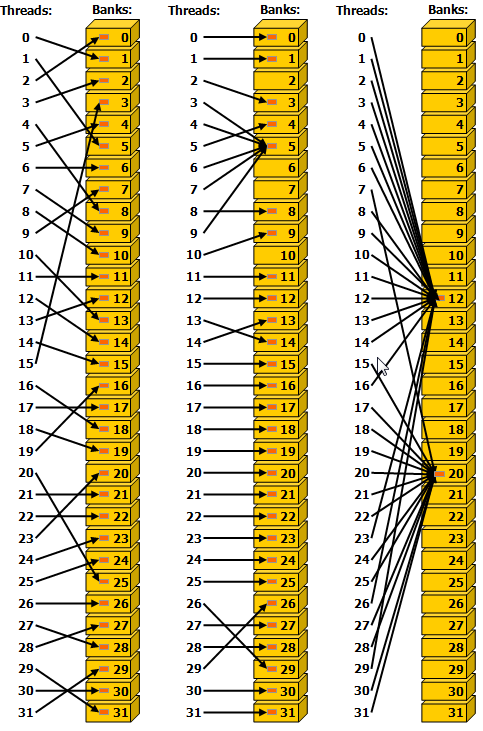
有一个例外是多个线程访问同一地址,读(broadcast 到所有线程)或写(有一个线程会写入,未定义行为)。
下图左右情况无 bank 冲突,中间有 2-way bank 冲突。
下图均为 conflict-free 情形。
3. 例子:方矩阵转置#
Naive 实现,假定 blockDim.x=32,blockDim.y=32,每个 block 处理 的 tile:
1/* macro to index a 1D memory array with 2D indices in row-major order */
2/* ld is the leading dimension, i.e. the number of columns in the matrix */
3
4#define INDX( row, col, ld ) ( ( (row) * (ld) ) + (col) )
5
6__global__ void naive_cuda_transpose(int m, float *a, float *c )
7{
8 int myCol = blockDim.x * blockIdx.x + threadIdx.x;
9 int myRow = blockDim.y * blockIdx.y + threadIdx.y;
10
11 if( myRow < m && myCol < m )
12 {
13 c[INDX( myCol, myRow, m )] = a[INDX( myRow, myCol, m )];
14 }
15 return;
16}相邻线程访问相邻的列,因此对 a 的读取是连续并 coalesced 的,但对 c 的写入是 strided 的,性能较差。
考虑使用 shared memory 作为线程块的 scratchpad,可以先将 tile 从 global memory 读入 shared memory 中,然后再从 shared memory 写回 global memory:
1#define INDX( row, col, ld ) ( ( (col) * (ld) ) + (row) )
2
3__global__ void smem_cuda_transpose(int m, float *a, float *c )
4{
5 __shared__ float smemArray[32][32];
6
7 const int myRow = blockDim.x * blockIdx.x + threadIdx.x;
8 const int myCol = blockDim.y * blockIdx.y + threadIdx.y;
9
10 /* determine my row tile and column tile index */
11
12 const int tileX = blockDim.x * blockIdx.x;
13 const int tileY = blockDim.y * blockIdx.y;
14
15 if( myRow < m && myCol < m )
16 {
17 /* read from global memory into shared memory array */
18 smemArray[threadIdx.x][threadIdx.y] = a[INDX( tileX + threadIdx.x, tileY + threadIdx.y, m )];
19 }
20
21 __syncthreads();
22
23 if( myRow < m && myCol < m )
24 {
25 /* write the result from shared memory to global memory */
26 c[INDX( tileY + threadIdx.x, tileX + threadIdx.y, m )] = smemArray[threadIdx.y][threadIdx.x];
27 }
28 return;
29}现在对 a 的读取和对 c 的写入都是连续并 coalesced 的,性能得到提升。
然而有另一个问题: 的 shared memory 每一列都在同一个 bank 中,因此在“从 global memory 读到 shared memory array”的过程中,整个 warp 中的线程都在访问同一个 bank,串行过后效率只有 1/32。
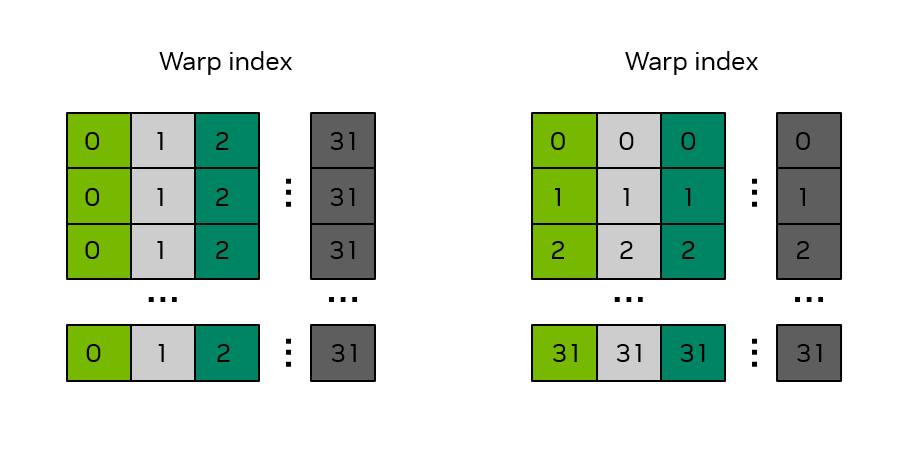
一个简单的解决办法是将 shared memory array 的维度改为 :
1__shared__ float smemArray[32][33];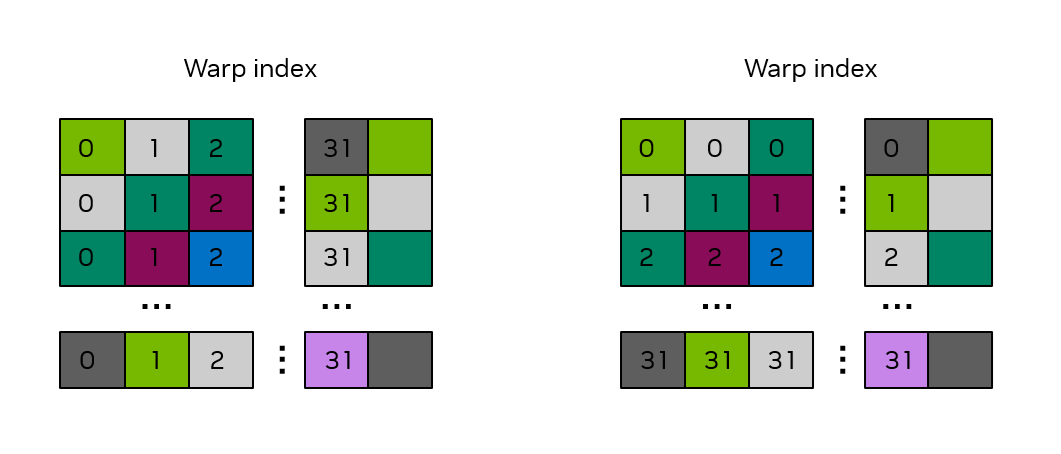
这个思路比较像 CPU 编程中的 cache line padding,牺牲了一点空间来避免 bank conflict。
对以上三种实现进行性能测试:
1device : NVIDIA GeForce RTX 4090
2matrix : 2048 x 2048 (16.00 MiB)
3grid/block : (64, 64) / (32, 32)
4iterations : 10000
5traffic/run : 32.00 MiB (read + write)
6
7kernel avg(us) total(ms) bandwidth(GB/s) valid
8naive 116.805 1168.047 287.27 yes
9smem 24.639 246.389 1361.85 yes
10smem+pad 14.091 140.910 2381.27 yes和预期结果一致。
三、利用率#
kernel 的利用率 occupancy 定义为活跃 warp 数量和 SM 最大线程数量的比值。
首先,内核启动过后,哪些线程块被调度到哪些 SM 上执行是由 GPU 硬件自动决定的,也无法保证其顺序,所以程序的正确执行不能依赖于特定调度顺序。
当内核首次启动时,调度器开始将 block 分配给 SM 执行。如果当前没有空闲的资源(如寄存器、shared memory 或者线程数量)来容纳新的 block,那么调度器会等待直到有足够资源的 block 结束执行并释放资源。
每个 SM 上的 block 数量受到如下资源限制的影响:
- Block 数量:
maxBlocksPerMultiProcessor,一个 SM 上可以同时执行的 block 数量的上限。 - 寄存器数量:
regsPerBlock, regsPerMultiprocessor,每个 block 需要的寄存器数量决定了一个 SM 上可以同时执行多少 block。 - Shared Memory:
sharedMemPerBlock, sharedMemPerMultiprocessor,每个 block 需要的 shared memory 大小决定了一个 SM 上可以同时执行多少 block。 - 线程数量:
maxThreadsPerBlock, maxThreadsPerMultiProcessor,每个 block 需要的线程数量决定了一个 SM 上可以同时执行多少 block。
作为参考,计算能力 10.0 的 GPU 资源限制如下:
| Resource | Value |
|---|---|
| maxBlocksPerMultiProcessor | 32 |
| sharedMemPerMultiprocessor | 233472 |
| regsPerMultiprocessor | 65536 |
| maxThreadsPerMultiProcessor | 2048 |
| sharedMemPerBlock | 49152 |
| regsPerBlock | 65536 |
| maxThreadsPerBlock | 1024 |
真实的利用率是上述四个限制中最严格的那个决定的。例如:
- 使用
testKernel<<<512, 768>>>启动的 kernel,每个 SM 至多同时执行 2 个 block(受maxThreadsPerMultiProcessor限制),occupancy 为 75%。 - 使用
testKernel<<<512, 32>>>启动的 kernel,每个 SM 至多同时执行 32 个 block(受maxBlocksPerMultiProcessor限制),occupancy 为 50%。 - 使用 100KB shared memory 的 kernel,每个 SM 至多同时执行 2 个 block(受
sharedMemPerMultiprocessor限制)。
我们对 register 使用的控制有限,不过可以通过 nvcc 的 -maxrregcount 选项来限制每个 block 使用的最大寄存器数量。如果 kernel 需要的寄存器数量超过这个值就很可能会发生寄存器溢出。在某些情况下,即使发生溢出,因为限制寄存器数量可以调度更多 block 增加 occupancy,性能反而会提升。