一、从生成模型出发#
生成模型的目标是学习数据分布 pdata(x),并能够从模型中采样出与真实数据相似的样本。
一种常见思路是先定义一个简单的潜变量分布:
z0∼π(z)
其中 π(z) 通常取标准高斯分布 N(0,I)。然后用一个生成器 G 把简单分布映射到复杂的数据空间:
x=G(z0)
这对应了一个非常直观的生成过程:
- 从简单先验 π(z) 中采样一个噪声变量 z0
- 通过映射 G 得到样本 x
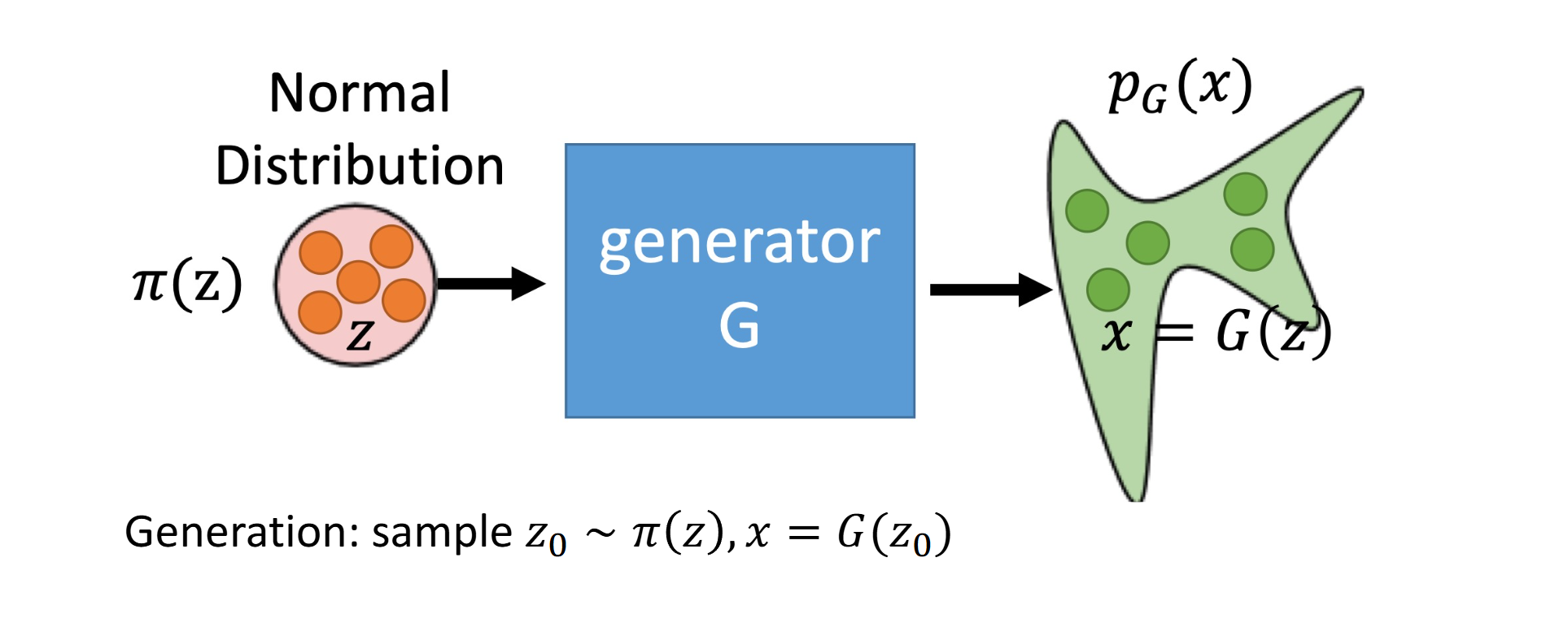
这里的关键问题是:如果只知道采样过程,能不能显式写出生成后的概率密度 p(x)?
对于一般生成器,答案往往是否定的;但如果 G 是可逆且可微的,那么就可以用变量变换公式精确计算密度。这正是 Normalizing Flow 的基础。
二、变量变换公式#
1. 一维情形#
设
x=G(z),z=G−1(x)
在一个很小的区间内,概率质量守恒:
p(x′)Δx=π(z′)Δz
因此有:
p(x′)=π(z′)dxdz
也就是:
p(x)=π(G−1(x))dxdG−1(x)
2. 多维情形#
在多维空间中,导数要推广为雅可比矩阵。若 G:Rd→Rd 可逆且可微,则:
p(x)=π(z)∣det(JG−1(x))∣,z=G−1(x)
其中:
JG−1(x)=∂x∂G−1(x)
这个式子的本质仍然是“概率质量守恒”,只是:
- 一维里的长度缩放,变成了多维里的体积缩放
- 体积缩放由雅可比行列式刻画
于是对数密度可以写成:
logp(x)=logπ(G−1(x))+log∣det(JG−1(x))∣
这一步把生成模型训练转化成了一个可计算的最大似然问题。
三、Normalizing Flow#
1. 为什么叫 Flow#
Normalizing Flow 的核心做法是:不直接用一个复杂的大映射,而是把它拆成很多个简单、可逆、且雅可比行列式容易计算的变换。
设:
zk=fk(zk−1),k=1,2,…,K
则整体变换为:
x=zK=fK∘fK−1∘⋯∘f1(z0)
其中 z0∼π(z)。
因为每一层都可逆,所以整体也可逆:
z0=f1−1∘f2−1∘⋯∘fK−1(x)
这类“逐层流动”的可逆变换就叫做 flow。
2. 对数似然分解#
对单层变换 zk=fk(zk−1),变量变换公式给出:
logpk(zk)=logpk−1(zk−1)−logdet(∂zk−1∂fk)
把 K 层连起来,得到:
logpK(zK)=logp0(z0)−k=1∑Klogdet(∂zk−1∂fk)
如果把 p0 取成简单先验 π(z),并记最终输出 zK=x,那么:
logp(x)=logπ(z0)−k=1∑Klogdet(∂zk−1∂fk)
其中 z0 由对 x 做逆变换得到。
因此,flow 的训练目标通常就是最大化数据的对数似然:
θmaxx∈D∑logpθ(x)
这和 GAN 的一个关键区别在于:flow 是显式似然模型,可以直接做最大似然训练。
四、可逆变换的设计要求#
Normalizing Flow 能不能训练得好,取决于每个子变换 fk 的设计。理想的层要同时满足三点:
- 可逆
- 逆变换易于计算
- 雅可比行列式易于计算
否则虽然理论上可以写出变量变换公式,但计算成本会非常高。
下面是一些常见结构的复杂度对比:
| 类型 | 逆复杂度 | 行列式复杂度 |
|---|
| 全连接 | O(d3) | O(d3) |
| 对角 | O(d) | O(d) |
| 三角 | O(d2) | O(d2) |
| 块对角 | O(c3d) | O(c3d) |
| LU 分解 | O(d2) | O(d) |
| 空间卷积 | O(dlogd) | O(d) |
| 1×1 卷积 | O(c3+c2d) | O(c3) |
Normalizing Flow 的结构设计是在表达能力与可计算性之间做平衡。
五、耦合层(Coupling Layer)#
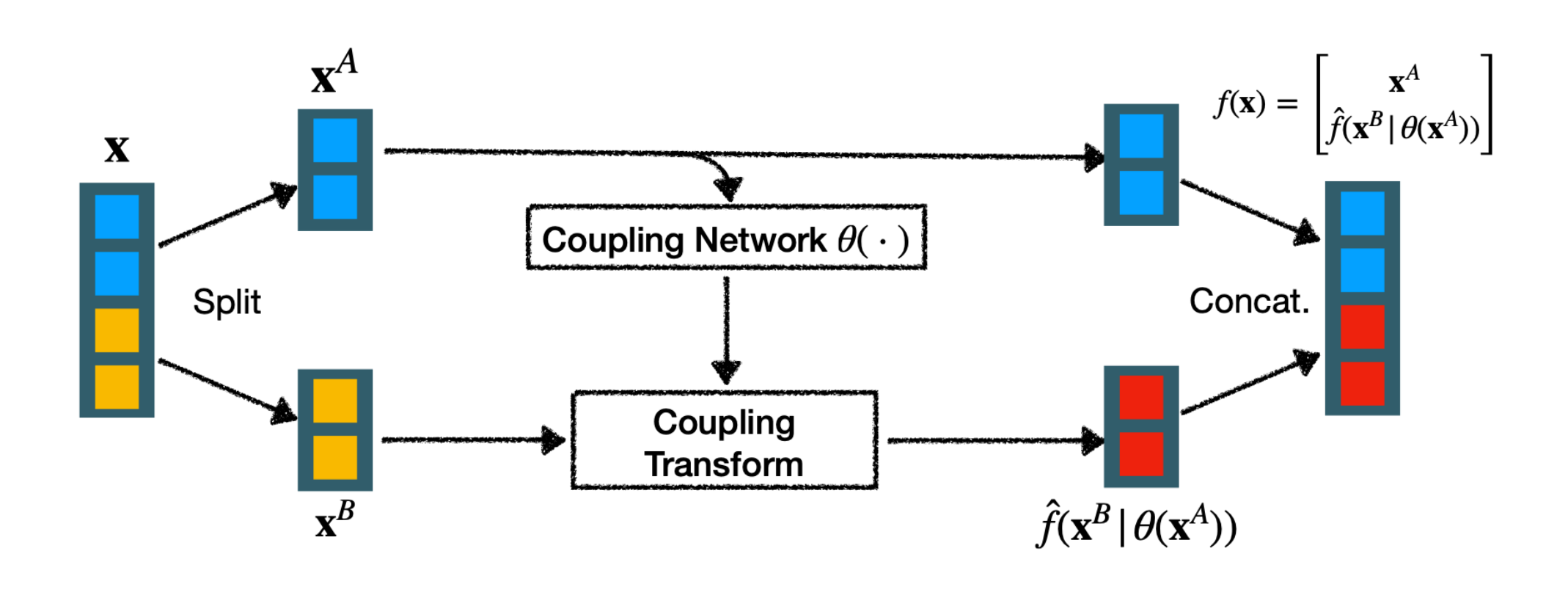
耦合层是 flow 中最经典的一类结构。它的思想很简单:把输入分成两部分,只变换其中一部分,另一部分作为条件控制参数。
1. 定义#
把输入拆成:
x=(xA,xB)
定义变换:
f(x)=[xAf^(xB∣θ(xA))]
含义是:
- xA 原样保留
- xB 在条件 θ(xA) 控制下发生变换
这样设计的好处是,雅可比矩阵天然是块三角形式。
2. 雅可比与行列式#
它的雅可比矩阵为:
Jf=[I∂xA∂f^0Jf^]
块三角矩阵的行列式等于对角块行列式之积,因此:
det(Jf)=det(Jf^)
这个结果非常关键,因为它意味着:
- 不需要计算完整雅可比矩阵的行列式
- 只需要计算被变换那一部分的雅可比行列式
于是高维情况下也能高效训练。
3. 常见耦合变换#
i. 加性耦合(NICE, 2014)#
定义:
f^(x∣t)=x+t
于是:
yA=xA,yB=xB+t(xA)
它的优点是逆变换简单:
xB=yB−t(yA)
但缺点也很明显:局部体积不变,因此:
log∣detJ∣=0
表达能力相对有限。
ii. 仿射耦合(RealNVP, 2016)#
定义:
f^(x∣s,t)=s∘x+t
更常见的写法是让网络输出 logs,再指数化保证尺度非零:
yA=xA,yB=exp(α(xA))∘xB+t(xA)
逆变换为:
xB=(yB−t(yA))∘exp(−α(yA))
此时雅可比是对角的,因此:
log∣detJ∣=i∑αi(xA)
这比加性耦合更灵活,也是现代 flow 中非常常见的基本模块。
4. 耦合层的局限#
单个耦合层并不会同时变换所有维度,因为总有一部分变量被原样保留。为了让所有通道都能逐步混合起来,通常需要在耦合层之间加入:
Glow 中的可逆 1×1 卷积就是为了解决这个问题。
六、可逆 1×1 卷积#
1. 为什么需要它#
早期模型常用固定置换来打乱通道顺序,但固定置换表达能力有限。Glow 的做法是学习一个可逆的线性变换,让不同通道之间能够更充分地混合。
设输入特征图:
h∈Rc×H×W
用一个权重矩阵:
W∈Rc×c
对每个空间位置的通道向量做同一个线性变换,输出维度不变。
只要 W 可逆,这个卷积就是可逆的。
2. 行列式计算#
对于每个空间位置,变换的雅可比都是 W;而空间上一共有 H×W 个位置,因此整体对数行列式为:
logdet(dhdconv2D(h;W))=H⋅W⋅log∣det(W)∣
这个公式非常漂亮:
- 图像越大,重复次数越多
- 真正需要计算的只是一个 c×c 矩阵的行列式
3. LU 分解重参数化#
为了进一步降低计算开销,可以把 W 参数化为:
W=PL(U+diag(s))
其中:
- P 是固定置换矩阵
- L 是对角线为 1 的下三角矩阵
- U 是严格上三角矩阵
- diag(s) 提供对角项
因为三角矩阵的行列式等于对角线元素之积,所以:
log∣det(W)∣=i∑log∣si∣
这样就把原本昂贵的矩阵行列式计算,转成了对角元素求和,复杂度降到 O(c)。
七、离散数据与去量化(Dequantization)#
很多真实数据是离散的,例如 8-bit 图像像素只取 0 到 255 的整数值。但 flow 建模的是连续密度 p(x),如果直接拿连续模型去拟合离散点,会出现奇异问题:
- 模型可能把概率质量集中在离散点附近
- 对应的密度可以趋于无穷大
- 最大似然训练因此变得不合理
解决办法是先给离散数据加上连续噪声,把它变成连续变量。设离散观测为 y,加入噪声 u 后得到:
x=y+u
对应的离散概率可以写成:
pd(y)=∫pmodel(y+u)p(u)du≈K1k=1∑Kpmodel(y+uk)
最常见的选择是均匀去量化:
u∼Uniform([0,1)d)
这样每个离散像素都会扩展成一个连续的小立方体,flow 就是在这些连续区域上建模密度。
八、Glow#
Glow 是一类非常有代表性的 flow 模型。
Glow: Generative Flow with Invertible 1x1 Convolutions
一个典型的 Glow step 通常包含:
- ActNorm
- 可逆 1×1 卷积
- 仿射耦合层
其设计逻辑很清楚:
- ActNorm 负责稳定每个通道的尺度
- 可逆 1×1 卷积负责通道混合
- 仿射耦合层负责提供非线性、可逆、且易求行列式的变换
Glow 的意义:只要可逆层设计得足够好,flow 可以在图像生成上做到相当强的表达能力,同时保留精确似然。
九、连续时间 Normalizing Flow#
前面的 flow 都是离散层堆叠:
z0→z1→⋯→zK
进一步可以把层数推向无限,把离散变换看成连续时间上的动力系统,这就得到 连续时间标准化流,也常称为 Neural ODE / Continuous Normalizing Flow (CNF)。
1. ODE 形式#
设状态随时间演化:
dtdz(t)=f(z(t),t,θ)
则从 t0 演化到 t1 的结果为:
z(t1)=z(t0)+∫t0t1f(z(t),t,θ)dt
这表示样本不再经过若干离散层,而是沿着向量场 f 连续流动。
2. 瞬时变量变换公式#
离散 flow 的难点之一是每层都要算一个行列式。连续时间情形下,这个问题转化为散度(trace)计算:
dtdlogp(z(t))=−Tr(∂z(t)∂f)=−div(f)
这是连续版的变量变换公式。它说明:
- 若向量场在局部把体积“压缩”,密度会上升
- 若向量场在局部把体积“膨胀”,密度会下降
与离散 flow 相比,这里不再需要直接计算 Jacobian determinant,而是计算 Jacobian 的迹,很多时候会更高效。
3. 训练目标#
对上式从 0 积分到 t,得到:
logp(z(t))=logp(z(0))−∫0tTr(∂z(τ)∂f)dτ
因此负对数似然可以写成:
L(z(t))=−logp(z(t))=−logp(z(0))+∫0tTr(∂z(τ)∂f)dτ
这个形式和离散 flow 一脉相承,只不过有限求和变成了时间积分。
4. 伴随方法(Adjoint Method)#
连续系统训练时,不能像普通深层网络那样简单保存所有中间状态,因此通常使用伴随方法来反向传播。
定义伴随变量:
a(t)=∂z(t)∂L
则它满足反向 ODE:
dtda(t)=−a(t)T∂z∂f
参数梯度则为:
dθdL=−∫t1t0a(t)T∂θ∂fdt
这意味着:
- 前向先解一次 ODE 得到状态轨迹
- 反向再解一个伴随方程得到梯度
连续时间 flow 因此在理论上很优雅,但训练效率和数值稳定性往往更依赖 ODE 求解器的实现。