零、我自己的理解#
如果整篇文章都是 AI 生成的就没意思了。
谈到 Variational Autoencoder,首先得知道什么是 Autoencoder(AE)。
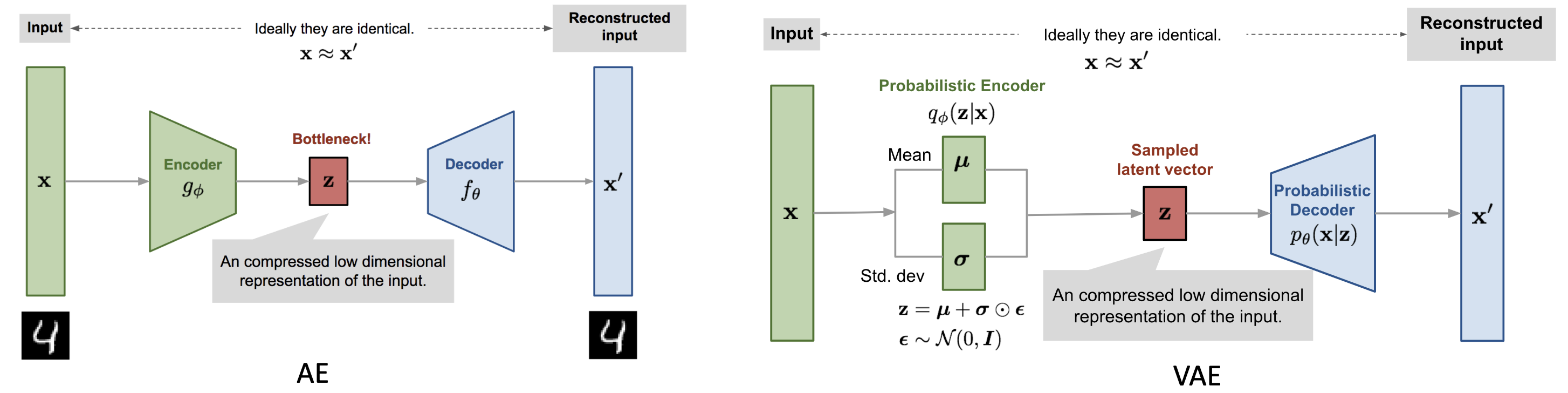
AE 假设数据 x 的分布可以通过一个低维潜变量 z 生成。Encoder 把输入映射到潜空间:z=g(X),Decoder 则从潜变量重建输入:X~=f(z)。有点类似于 PCA,但 AE 是非线性的。AE 的训练目标是最小化重建误差:∥X−X~∥2。
但是 AE 的问题是它没有明确的概率解释,生成质量不稳定,潜空间结构也不规整。我们首先假设 latent space 的先验分布是标准正态分布 p(z)=N(0,I),我们希望 Decoder 能够根据这些 latent variables 的值(代表的潜在语义)生成合理的样本。
既然要建模真实数据分布,那么大量从 latent space 采样,然后最大化似然可不可以呢?
θmaxlogpθ(x)=θmaxlog∫p(z)pθ(x∣z)dz
不行,因为 latent space 维度也没那么低,采样估计积分的话方差太大了。正确做法是重要性采样减小方差,引入一个可学习的 proposal 分布 qϕ(z∣x) 来近似真实后验 pθ(z∣x),从而得到这个 likelihood 的一个可优化的下界(ELBO):
L(x;θ,ϕ)=Eqϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∥p(z))
在优化这个 ELBO 的过程中,第一项鼓励 Decoder 在给定 latent variables 时能较好地重建输入;第二项则要求 encode 后的 latent variable 分布不要偏离先验太多,从而保证潜空间的规整性。
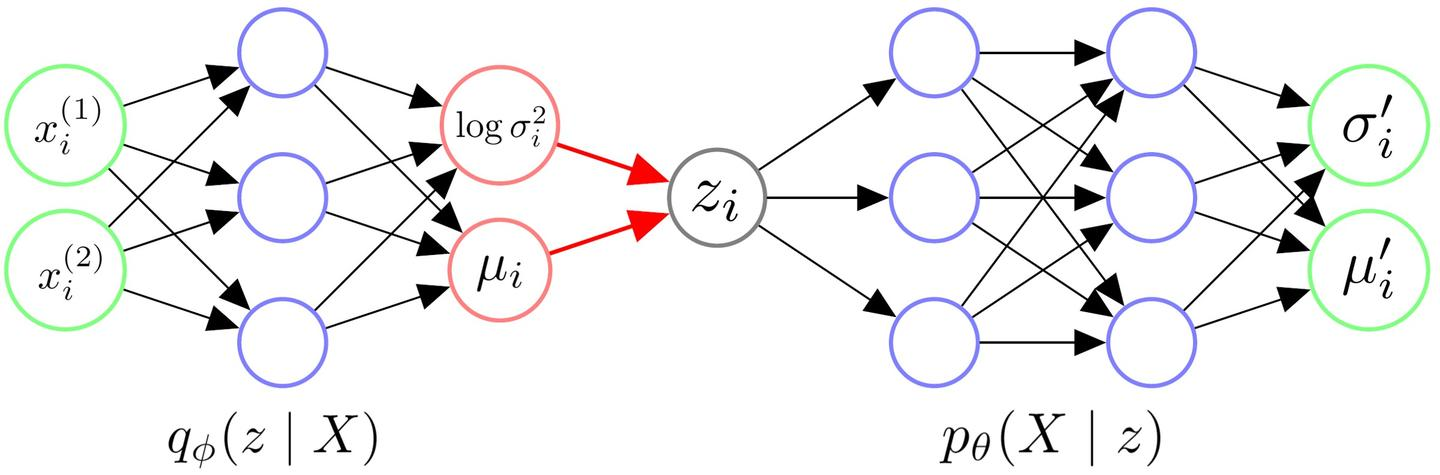
换句话说,Encoder 模拟了 qϕ(z∣x) 这个函数,生成高斯分布的均值和方差;在利用了 reparameterization trick 之后,把采样出的 latent variable 送入 Decoder,得到重建的样本。需要优化的目标函数就是上面这个 ELBO,反向传播更新 Encoder 和 Decoder 的参数,就能逼近真实的 log-likelihood。
值得一提的是,我们针对 VAE 引入了如下假设:
- 先验分布 p(z) 是标准高斯分布 N(0,I)
- 近似后验 qϕ(z∣x) 是一个条件高斯分布 N(μϕ(x),diag(σϕ2(x)))
- 解码器 pθ(x∣z) 也是一个条件高斯分布 N(ψθ(z),βI)
这三个假设在设计上肯定不是乱选的。
- 前两个分布被捆在一起,KL 项要有 closed-form 解才好优化。
- 第三个假设则是为了让重建项对应一个带噪声的最小二乘误差 Eqϕ(z∣x)∥x−ψθ(z)∥2,比较自然。
- qϕ 要能重参数化,才能用 Monte Carlo 采样和反向传播联合训练。
当然这个分布的形式可以有变体,比如 Gaussian Mixture Variational Auto-Encoder 就是把先验换成了高斯混合分布。
一、从概率生成模型出发#
生成模型的目标是学习数据分布 pdata(x),从而既能评价一个样本出现的概率,也能生成新的样本。
一种自然的建模方式是引入潜变量 z,把复杂数据 x 的生成过程拆成两步:
- 先从简单先验分布中采样潜变量
z∼π(z)
- 再根据潜变量生成观测
x∼pθ(x∣z)
于是模型边缘分布为:
pθ(x)=∫pθ(x∣z)π(z)dz
这类模型叫做概率生成模型(probabilistic generative model)。它的核心特征是:
- z 负责刻画隐含语义
- pθ(x∣z) 负责把语义映射为观测
- 真正可见的数据分布 pθ(x) 由对潜变量积分得到
训练时最直接的目标是最大化对数似然:
θmaxlogpθ(x)
也就是让训练数据在模型下的概率尽可能大。
如果生成器 G 是确定性的,且可逆可微:
x=G(z)
那么可以直接用变量变换公式计算密度:
p(x)=π(G−1(x))∣detJG−1(x)∣
其中 JG−1(x) 是逆变换的雅可比矩阵。
这说明:如果生成过程足够规整,可显式写出似然;但一般深度生成模型并不满足“易求逆且易算雅可比”的条件,因此需要其它思路。VAE 正是在“显式概率建模”和“可扩展深度模型”之间取得平衡的一种方法。
二、GMM:离散隐变量情形#
在进入 VAE 之前,可以先看最经典的隐变量模型之一:高斯混合模型(Gaussian Mixture Model, GMM)。
设潜变量 z 只取有限个离散值:
p(z=j)=πj,j=1,…,K,j=1∑Kπj=1
给定分量编号 z=j 后,观测满足高斯分布:
p(x∣z=j)=N(x∣μj,Σj)
因此边缘分布为:
p(x)=j=1∑KπjN(x∣μj,Σj)
这里每个高斯分量对应数据空间中的一个“簇”,πj 表示该簇的先验概率。
K-means 可以看成 GMM 的一个极限情形:
- 各分量协方差相同,且趋于很小
- 后验分配趋于 one-hot
- 优化目标从对数似然退化为最近中心划分
因此,GMM 比 K-means 更一般:它给出的是软分配而不是硬划分。
三、GMM 的 EM 优化#
对于样本 {xi}i=1N,GMM 的对数似然为:
i=1∑Nlogj=1∑KπjN(xi∣μj,Σj)
难点在于:对数作用在求和外面,直接优化比较困难。
1. 后验责任度#
定义样本 xi 由第 j 个分量生成的后验概率:
γij=p(zi=j∣xi)=∑k=1KπkN(xi∣μk,Σk)πjN(xi∣μj,Σj)
它通常被称为责任度(responsibility)。
2. EM 算法#
EM 的基本想法是:如果隐变量 zi 已知,那么极大似然会很容易;既然不知道,就交替优化“隐变量的分布”和“模型参数”。
对任意满足 ∑jγij=1 的分布,利用 Jensen 不等式有:
i∑logj∑πjN(xi∣μj,Σj)=i∑logj∑γijγijπjN(xi∣μj,Σj)≥i∑j∑γijlogγijπjN(xi∣μj,Σj)
这就是 GMM 的一个 ELBO。
于是得到 EM 两步:
Expectation#
固定参数 (πj,μj,Σj),更新责任度
γij=p(zi=j∣xi)
也就是把 γij 取成真实后验。
Maximization#
固定 γij,最大化下界,更新模型参数:
πj=N1i=1∑Nγij
同时还可得到:
μj=∑iγij∑iγijxi,Σj=∑iγij∑iγij(xi−μj)(xi−μj)T
先估计隐变量的后验,再在这个后验下最大化完整数据对数似然的期望。
四、从 EM 到 ELBO#
GMM 里用到的下界技巧可以推广到更一般的结论。对任意潜变量模型
pθ(x)=∫p(z)pθ(x∣z)dz
引入任意分布 qx(z),有:
logpθ(x)=log∫qx(z)qx(z)p(z)pθ(x∣z)dz
由于 log 是凹函数,利用 Jensen 不等式得到:
logpθ(x)≥∫qx(z)logqx(z)p(z)pθ(x∣z)dz
把右边拆开:
L(x;θ,q)=Eqx(z)[logpθ(x∣z)]−KL(qx(z)∥p(z))
这就是 ELBO(Evidence Lower Bound,证据下界)。
其中两项分别表示:
- 重建项
Eqx(z)[logpθ(x∣z)]
它鼓励模型在给定潜变量时能较好地重构输入。
- 正则项
KL(qx(z)∥p(z))
它要求编码后的潜变量分布不要偏离先验太多。
ELBO 之所以重要,是因为它与真实后验有精确关系:
logpθ(x)−L(x;θ,q)=KL(qx(z)∥pθ(z∣x))
证明:
KL(qx(z)∥pθ(z∣x))=∫qx(z)logpθ(z∣x)qx(z)dz=∫qx(z)logp(z)pθ(x∣z)qx(z)pθ(x)dz=logpθ(x)−∫qx(z)logqx(z)p(z)pθ(x∣z)dz=logpθ(x)−L(x;θ,q)
因为 KL 散度总是非负,所以 ELBO 一定不超过真实对数似然;当且仅当
qx(z)=pθ(z∣x)
时,下界与真实对数似然重合。
所以可以把 VAE 看成“把 EM 推广到连续高维潜变量和神经网络参数化”的方法。
五、为什么需要变分近似#
理想情况下,我们希望直接使用真实后验 pθ(z∣x)。但在深度生成模型中:
- 边缘似然 pθ(x)=∫p(z)pθ(x∣z)dz 往往不可积
- 后验 pθ(z∣x) 也通常没有解析形式
- 直接采样估计对数似然方差很大,训练不稳定
因此需要引入一个可学习的近似后验 qϕ(z∣x),用它来逼近真实后验。
此时训练目标写为:
ϕ,θmaxEqϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∥p(z))
这里:
- ϕ 是编码器参数
- θ 是解码器参数
六、从重要性采样理解 VAE#
VAE 还可以从重要性采样角度理解。
对于任意分布 p 和 proposal q,都有:
Ep[f(x)]=Eq[f(x)q(x)p(x)]
类似地,对边缘似然:
pθ(x)=∫qϕ(z∣x)qϕ(z∣x)p(z)pθ(x∣z)dz
如果 qϕ(z∣x) 很接近真实后验 pθ(z∣x),那么权重
qϕ(z∣x)p(z)pθ(x∣z)
的方差会更小,估计更稳定;如果恰好
qϕ(z∣x)=pθ(z∣x)
那么单样本估计就已经是精确的。
这说明编码器的作用像是在为生成模型构造一个高质量的 proposal 分布。
七、VAE 的基本形式#
1. 参数化#
VAE 的标准选择是:
qϕ(z∣x)=N(μϕ(x),diag(σϕ2(x)))
也就是让编码器输出潜变量高斯分布的均值和方差。
解码器通常定义条件分布:
pθ(x∣z)=N(ψθ(z),βI)
其中 ψθ(z) 是神经网络输出,β 控制观测噪声强度。
于是 ELBO 为:
L(x)=Eqϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∥p(z))
若先验取标准正态分布
p(z)=N(0,I)
则 KL 项可以显式写出。
2. 高斯解码器下的重建项#
由高斯密度公式:
logpθ(x∣z)=−2β1∥x−ψθ(z)∥22+C
其中 C 与参数无关。因此最大化 ELBO 等价于最大化
−2β1Eqϕ(z∣x)∥x−ψθ(z)∥22−KL(qϕ(z∣x)∥p(z))
VAE 的重建项本质上对应一个带噪声假设的最小二乘误差。
3. 高斯后验与标准正态先验的 KL 闭式解#
若
qϕ(z∣x)=N(μ,diag(σ2))
则
KL(qϕ(z∣x)∥N(0,I))=21k=1∑d(μk2+σk2−logσk2−1)
向量形式也可记为:
KL=21(∥μ∥22+k=1∑dσk2−k=1∑dlogσk2−d)
八、重建项与 KL 项分别在做什么#
VAE 的目标函数包含两个互相制衡的部分。
1. 重建项#
若只优化重建项:
Eqϕ(z∣x)[logpθ(x∣z)]
模型最倾向于让 qϕ(z∣x) 收缩成几乎确定的点分布,这样每个样本都可以被单独编码到最容易重建的位置。
2. KL 项#
KL 项
KL(qϕ(z∣x)∥p(z))
则会惩罚这种过度确定性的编码,因为点分布相对连续先验的 KL 往往趋向无穷大。
因此:
二者平衡后,潜空间既保留语义结构,又能从简单先验中稳定采样。
所以 VAE 生成质量和潜空间连续性之间存在典型 trade-off。
九、重参数化技巧#
VAE 的核心技术问题是:如何对
Eqϕ(z∣x)[logpθ(x∣z)]
求关于 ϕ 的梯度?
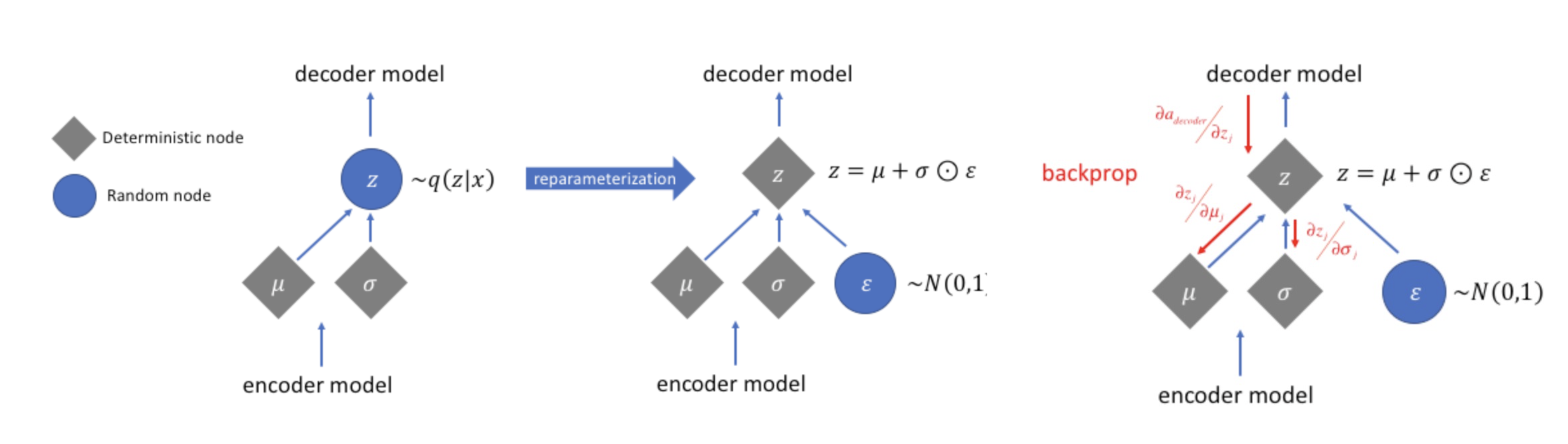
如果直接写成 z∼qϕ(z∣x),采样操作会切断梯度。解决方法是把随机性从参数里“拆出来”:
ϵ∼N(0,I),z=μϕ(x)+σϕ(x)⊙ϵ
这样随机变量只剩下与参数无关的 ϵ,而 z 是 ϕ 的可微函数。于是:
Eqϕ(z∣x)[logpθ(x∣z)]=Eϵ∼N(0,I)[logpθ(x∣μϕ(x)+σϕ(x)⊙ϵ)]
从而可以用 Monte Carlo 采样和反向传播联合训练编码器与解码器。
这一步称为重参数化技巧(reparameterization trick)。
十、VAE 学到了什么样的潜空间#
如果训练良好,VAE 的潜变量往往具有一定可解释性。例如:
- 改变某一维 z1,可能对应“是否微笑”
- 改变另一维 z2,可能对应“头部姿态”
这种现象说明潜空间中的某些方向与高层语义相关。虽然标准 VAE 不保证严格 disentanglement,但其连续、平滑的潜空间通常比普通自编码器更适合插值和控制生成。

十一、分层 VAE#
标准 VAE 只有一层潜变量:
z→x
但真实图像往往包含多尺度结构:
- 高层语义:物体类别、姿态、布局
- 低层细节:纹理、边缘、颜色
因此可以引入多层潜变量:
zL→zL−1→⋯→z1→x
1. 分层先验#
p(z1,…,zL)=p(zL)i=1∏L−1p(zi∣zi+1)
含义是:
- 最高层 zL 描述最抽象的全局语义
- 下层潜变量在更高层条件下逐步补充细节
2. 编码器近似#
一种简化的近似后验写法是:
q(z1,…,zL∣x)=i=1∏Lq(zi∣x)
它假设在给定 x 时,各层潜变量条件独立。这个假设并不最强,但计算方便。
3. ELBO 分解#
在上述结构下,ELBO 仍然由“重建项 + 多层 KL 项”组成。
−Ez1∼q(z1∣x)logp(x∣z1)+i=1∑LEq(zi∣x)[logp(zi∣zi+1)q(zi∣x)]
它的本质没有变化:
- 第一项要求最低层潜变量能够解释观测
- 后面各项要求每一层后验不要偏离对应的层次先验
分层结构的好处是可以把不同尺度的信息分摊到不同潜变量层中,从而提升表达能力。
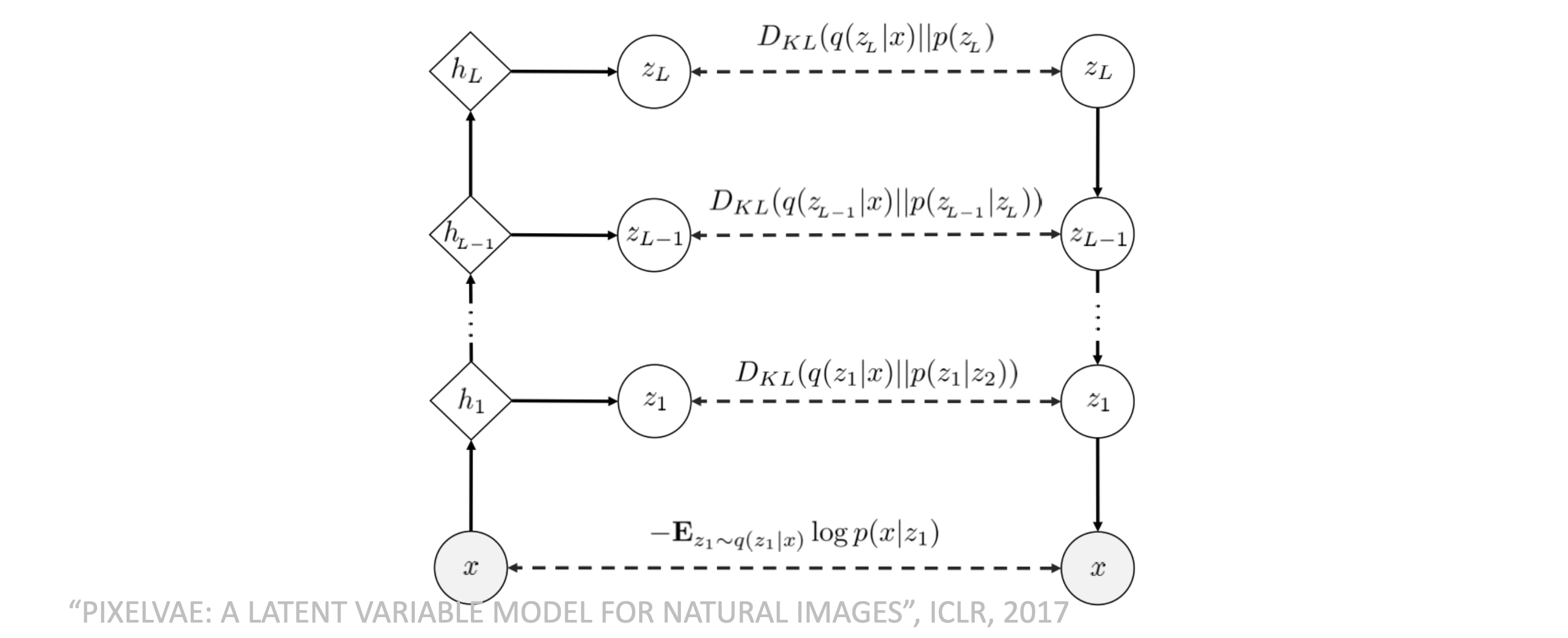
十二、Hierarchical PixelVAE 与 NVAE#
1. Hierarchical PixelVAE#
Hierarchical PixelVAE 的核心思想是:
- 用 VAE 负责建模全局结构
- 用 PixelCNN 一类自回归解码器负责建模局部像素依赖
这样做的动机是:普通 VAE 的解码器若过弱,会导致重建模糊;若过强,又容易忽略潜变量。将层次潜变量和像素级自回归结合,可以兼顾全局语义与局部细节。

2. NVAE 的基本思想#
NVAE 是更强的深层层次化 VAE。它通过非常深的卷积层次和更精细的分布建模,在 ImageNet 64×64 等任务上显著提升了 VAE 的生成质量。
q(z)=l=1∏Lq(zl∣z<l),p(z∣x)=l=1∏Lp(zl∣z<l,x)
并假设各层条件分布为高斯:
q(zl∣z<l)=N(μ(z<l),σ2(z<l))
p(zl∣z<l,x)=N(μ(z<l)+Δμ(z<l,x),σ2(z<l)⊗Δσ2(z<l,x))
这里的直观意义是:
- top-down 路径先给出一个层次化先验预测
- 再利用输入 x 对均值和方差做残差式修正
因此,后验不是完全重新预测一套参数,而是在先验基础上作增量更新,这有利于稳定训练并提高层次表达能力。
对应的 KL 可分解为逐层求和:
KL(p(z∣x)∥q(z))=KL(p(z1∣x)∥q(z1))+l=2∑LEp(z<l∣x)[KL(p(zl∣z<l,x)∥q(zl∣z<l))]
这说明整个模型的正则项可以拆成各层局部 KL 的累积,从而与层次结构天然匹配。
十三、总结#
1. 概率建模#
VAE 是一个带潜变量的概率生成模型:
pθ(x)=∫p(z)pθ(x∣z)dz
2. 推断#
真实后验 pθ(z∣x) 难算,于是引入可学习近似后验 qϕ(z∣x),并最大化 ELBO:
ϕ,θmaxEqϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∥p(z))
3. 优化#
重参数化
z=μϕ(x)+σϕ(x)⊙ϵ
把随机采样改写成可微计算图,从而可以直接用 SGD 训练。
VAE 本质上是在同时做两件事:
- 学一个生成模型 pθ(x∣z)
- 学一个近似推断器 qϕ(z∣x)